
The duplicate record clustering works on the principle of appending additional external identifiers to dataset records that identify relationships between the records.
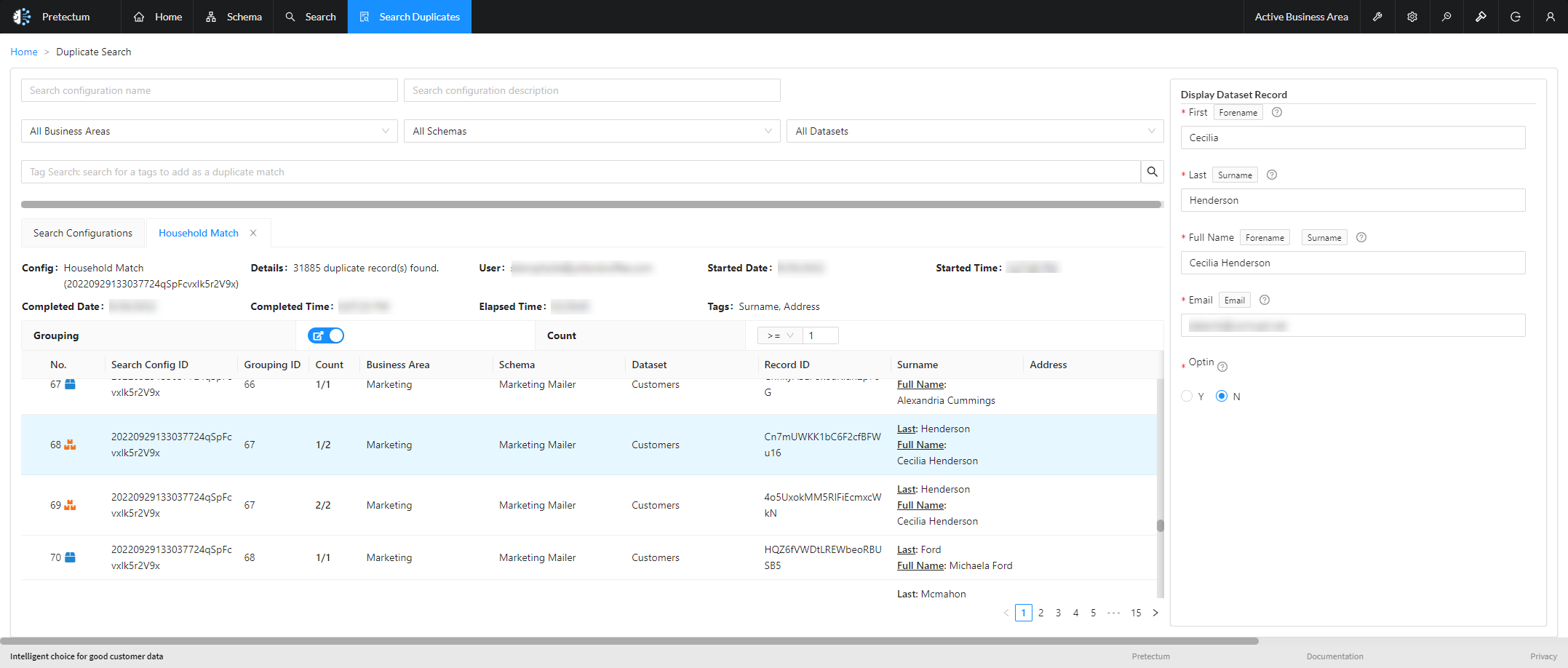
Clusters are denoted by a triple crown which can be contracted or expanded depending on the configuration of the list screen – the underlying data of each row is also visible in the right preview panel.
The cluster filter also allows you to filter out singletons and look for particularly large clusters depending on what has been established.